Video Results with Given Trajectory
IDCNet generates RGB-D scenes from input RGB-D data and given trajectories. Each row shows videos generated from different prompts under a shared trajectory.
IDCNet generates RGB-D scenes from input RGB-D data and given trajectories. Each row shows videos generated from different prompts under a shared trajectory.
Additional RGB-D results generated by IDCNet from varying input prompts and trajectories.
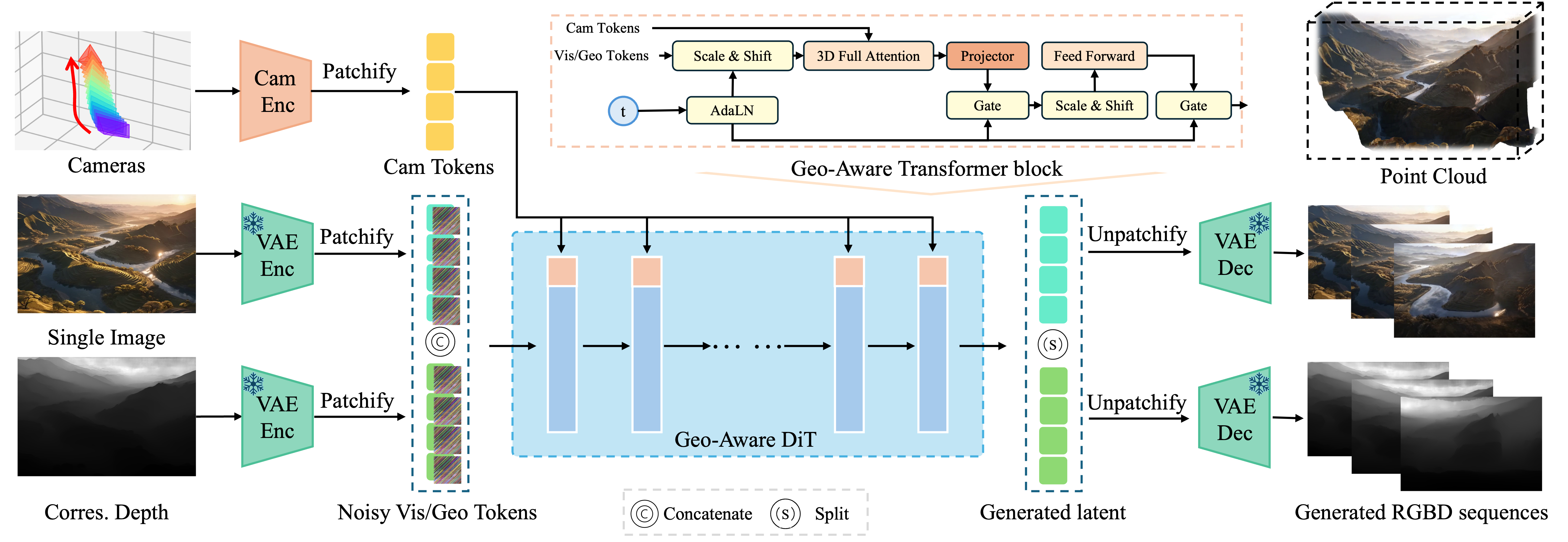
As the figure shown, IDC-Net jointly generates RGB and depth sequences in latent space, conditioned on an input frame and target camera trajectory. Camera poses are embedded through a GeoAware transformer to enforce spatial consistency. The generated metrically aligned RGB-D outputs enable direct point cloud extraction, supporting immediate downstream 3D reconstruction
@article{
liu2025idcnetguidedvideodiffusion,
author = {Lijuan Liu and Wenfa Li and Dongbo Zhang and Shuo Wang and Shaohui Jiao},
title = {IDCNet: Guided Video Diffusion for Metric-Consistent RGBD Scene Generation with Precise Camera Control},
eprint = {2508.04147},
year = {2025},
archivePrefix={arXiv},
url = {https://arxiv.org/abs/2508.04147},
}